0x1 强化学习简介
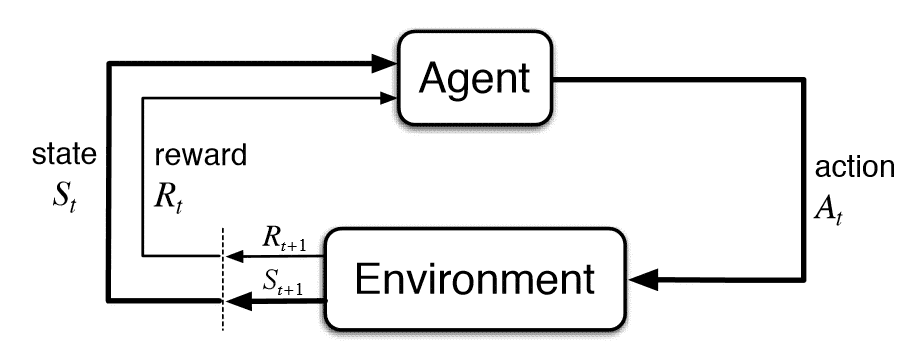
强化学习(Reinforcement Learning, RL)是机器学习(Machine Learning, ML)的三大分支之一。在一个强化学习问题中, 有一个决策者, 我们通常称之为智能体(agent), 它所交互的区域叫做环境(environment, env), 它所处的当前环境称为状态(state), agent观察到的这个环境状态称为(observation,obs), agent会根据observation, 根据自己的策略(policy)执行动作(action), 根据agent的action, 给agent相应的奖励(reward), 并同时进入到下一个state。就这样不断地重复, 直到env到达了一个终止状态(terminal state)(注:有的环境不存在终止状态)。agent在从开始到终止状态中所获得的reward之和。称之为回报(return)。agent的目的, 就是优化自己的policy,使得它的return最大。在没有特殊说明的情况下, 在本博客中提到的环境state等价于agent的observation,也就是env是完全可观察环境。如图, 是强化学习的状态转移图。强化学习具有以下特点:
- 以reward作为监督信号
- 反馈具有延后性(不是及时的)
- 处理的数据为序列数据而非独立同分布
0x2 MDP简介
RL是建立在环境具有马尔科夫性的假设上的,即下一个状态的产生只取决于当前的状态,而与之前的状态无关。即
P[St+1∣St]=P[St+1∣S1,...,St]
马尔可夫决策过程(Markov Decision Process, MDP)正式描述了强化学习的决策过程, MDP可以定义为<S,A,P,R,γ>, 分别表示state集合、action集合、状态转化概率、reward函数、衰减率。RL的policy有两种,确定性策略(deterministic policy)和随机性策略(stochastic policy),前者表示对于一个策略π,给定状态s,策略会给出一个动作a, 记为π(s)=a。而后者对于一个策略π, 给定状态s, 会给出执行动作空间里的每个动作的概率分布, 记为π(a∣s)=P[At=a∣St=s], 在此,我们同时也假设了策略π也符合马尔可夫假设,即此时采取动作a的概率只和当前的状态s有关,而与其他要素无关。我们可以定义出环境转移的概率为
Pss′=P[St+1=s′∣St=s]
在状态s处执行a的转移概率,可以定义为
Pss′a=P[St+1=s′∣St=s,At=a]
使用策略π,在状态s处执行动作后的转移概率,可以定义为
Pss′π=a∈A∑π(a∣s)Pss′a
在状态s处执行a,能获得的r的期望,可以定义为
Rsa=E[Rt+1=r∣St=s,At=a]
使用策略π,在状态s处执行动作后能获得的r的期望,可以定义为
Rsπ=a∈A∑π(a∣s)Rsa
我们使用状态价值函数(value function) Vπ(s)来衡量一个状态s的好坏,其值为从状态s开始的执行策略π的return的期望,表示为
Vπ(s)=Eπ[Gt∣St=s]
我们使用动作状态价值函数(Q function) Qπ(s,a)来衡量一个状态s下采取特定a的好坏,其值为从状态s开始执行特定a(与策略π无关)后,执行策略π的return的期望,表示为
Qπ(s,a)=Eπ[Rt+1+γ(Vπ(St+1))∣St=s,At=a]
0x3 贝尔曼期望方程与最优方程
贝尔曼期望方程(Bellman Expectation Equations), 将状态值函数V(s)与动作值函数Q(s,a)、将当前的值函数V(s)与之后状态V(s’)、将当前的动作值函数Q(s,a)与之后的动作的值函数Q(s’,a’)联系起来。其整体过程可以用这张图表示。
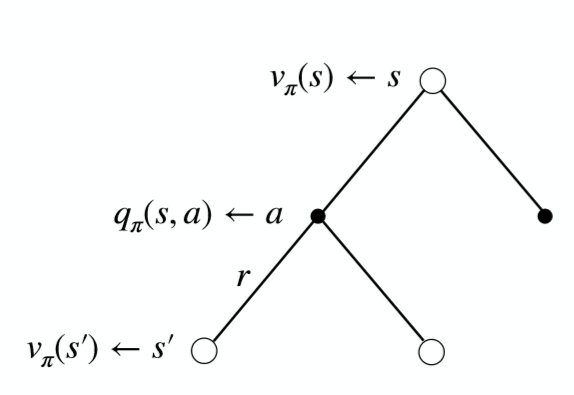
状态值函数V(s)与动作值函数Q(s,a)的关系
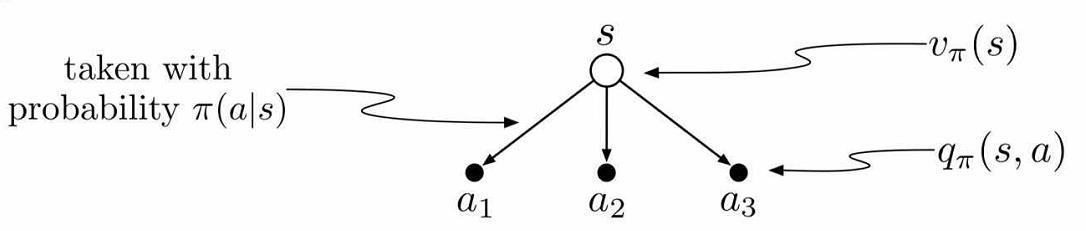
Vπ(s)=a∈A∑π(a∣s)Qπ(s,a)
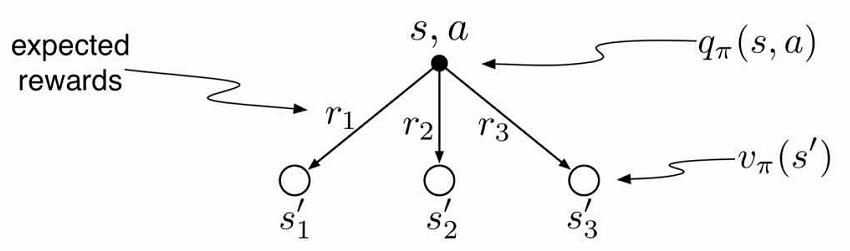
Qπ(s,a)=Rsa+γs′∈S∑Pss′aVπ(s′)
联系V(s)与V(s’)
将以上两式相结合,立刻得到
Vπ=a∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))
联系Q(s,a)与Q(s’,a’)
同理
Qπ(s,a)=Rsa+γs′∈S∑Pss′aa′∈A∑π(a′∣s′)Qπ(s′,a′)
最优价值函数
V∗(s)=πmaxVπ(s)
Q∗(s,a)=πmaxQπ(s,a)
贝尔曼最优方程
贝尔曼最优方程是在贝尔曼期望方程的基础上推理得到的。在策略π达到最优时,状态价值函数V与动作价值函数Q取最大a是相等的
V∗(s)=amaxQ∗(s,a)
Q∗(s,a)=Rsa+γs′∈S∑Pss′aV∗(s′)
V∗(s)=amax(Rsa+γs′∈S∑Pss′aV∗(s′))
Q∗(s,a)=Rsa+γs′∈S∑Pss′aamaxQ∗(s′,a′)
如果我们完全直到环境信息,则问题可以转化为一个规划问题,通过动态规划求解,但大部分时候我们不知道转移概率、reward函数,不能直接通过贝尔曼方程求解。




